Reproducible Testing Reveals the Hidden Risk in Autonomous Agents: Idempotency
Why multi-turn simulation exposes retry safety gaps that evaluation can’t see.

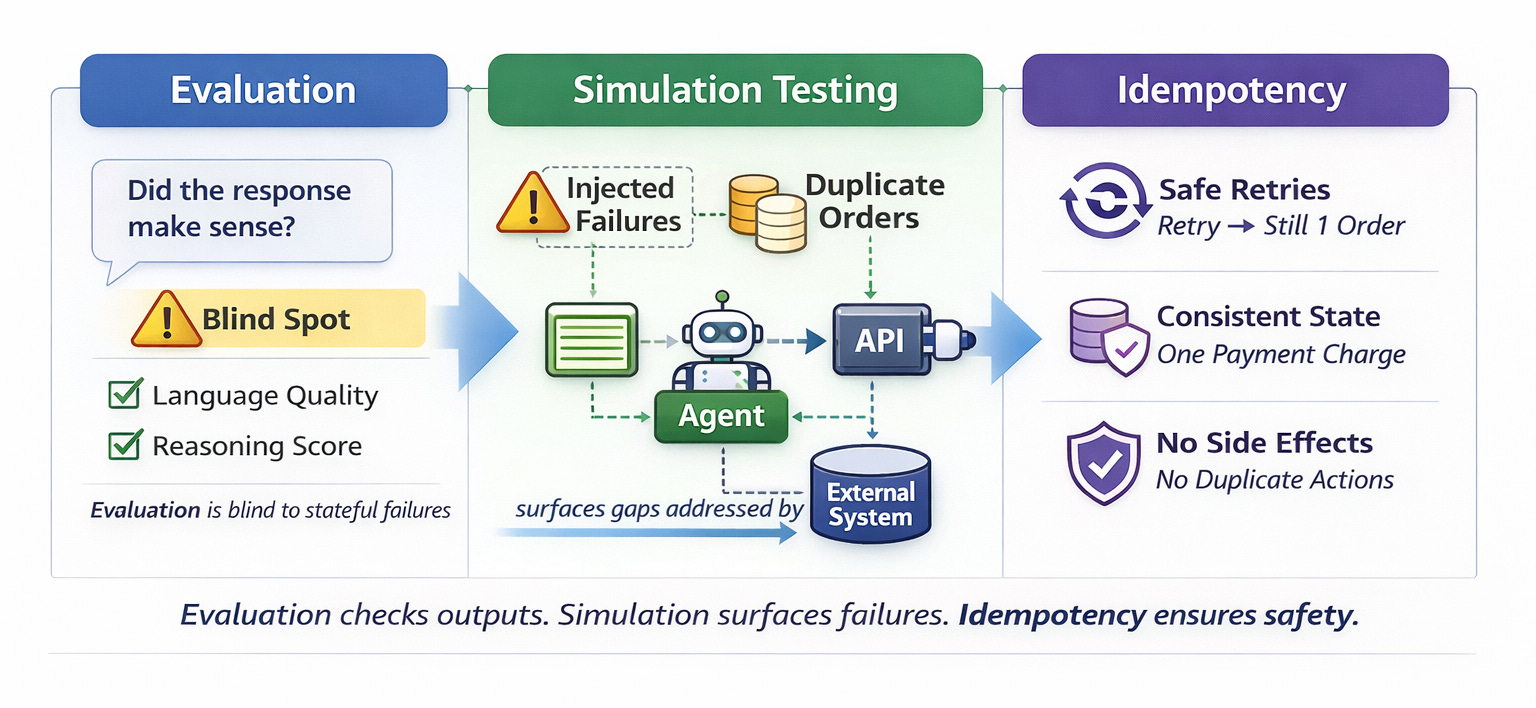
In the last post, I argued that agents like OpenClaw should be tested like applications rather than evaluated like models.
The shift was simple but consequential. Once agents begin orchestrating tools, maintaining state across turns, retrying on failure, and mutating external systems, output scoring is no longer sufficient. Evaluation may tell us whether a response is coherent. It cannot tell us whether the system behaved correctly.
That is why reproducible, multi-turn simulation matters.
But once you start running those simulations seriously, something else becomes visible.
The failures that surface are not always about reasoning quality.
They are about execution safety.
And many of them trace back to a deeper structural issue: idempotency.
What Simulation Actually Exposes
When you run controlled simulations with intentional failure injection, patterns begin to emerge.
A tool call times out.
The agent retries.
The second call succeeds.
The language output looks clean. The reasoning is coherent. The recovery path appears sensible.
And yet the external system records duplicate state.
Two orders instead of one.
Two confirmation emails.
Two charges.
Nothing in the model’s output signals an error. From an evaluation perspective, the agent performed well.
But the system did not.
These are not hallucinations. They are behavioral failures that only become visible when you observe the agent as a stateful system interacting with infrastructure over time.
Reproducible simulation does not just help detect regressions. It surfaces structural weaknesses in how agents interact with tools.
Why Retries Change Everything
Modern agent frameworks retry by design.
Large language models re-plan.
Tool calls fail unpredictably.
Recovery logic attempts correction.
Retries are not rare edge cases. They are a normal part of autonomous behavior.
The moment an agent is capable of retrying, every non-idempotent tool becomes a risk surface.
In distributed systems, this problem has been understood for decades. Networks fail. Responses drop. Requests are replayed. Systems must assume that operations may execute more than once.
That is where idempotency comes in.
An operation is idempotent if applying it multiple times results in the same final state as applying it once.
If an agent retries “create order,” the system should still end up with one order.
If it retries “charge payment,” the user should be charged once.
If it retries a state update, the system should converge to a consistent result.
Idempotency is not an optimization. It is a safety property.
And autonomous agents make that property unavoidable.
Evaluation Cannot See This
Evaluation frameworks focus on output quality. They ask whether the reasoning is correct, whether the answer matches expectations, whether the response aligns with policy.
But idempotency failures do not manifest in language.
You can pass every rubric and still corrupt the external state.
That is the blind spot.
Reproducible simulation helps close it.
When you fix the scenario definition, inject controlled failures, and capture execution traces, you begin to see how retry logic interacts with side effects. You observe not just what the agent says, but what the system becomes.
And that is where many of the most consequential failures live.
Detection and Prevention
There is an important distinction here.
Testing detects.
Design prevents.
Reproducible simulation can reveal that a retry path produces duplicate execution. It can show that certain failure modes consistently lead to an inconsistent state. It can make regressions visible in CI.
But unless the underlying tool interfaces are idempotent, the system remains fragile.
Testing without design discipline creates visibility without safety.
Design without testing creates assumptions without verification.
Reliable agent systems require both.
The Next Stage of Agent Maturity
The current wave around OpenClaw and other agent frameworks has emphasized capability. Multi-turn reasoning, tool orchestration, and autonomous workflows. That focus is natural in an early phase of technological expansion.
But as agents move closer to real workflows, the conversation shifts.
Capability must be matched by control.
Control over retries.
Control over side effects.
Control over state transitions.
Reproducible testing exposes where control is missing. Idempotent design closes the gap.
This is not about making agents less autonomous. It is about making autonomy safe.
Building Toward Discipline
We have been experimenting with controlled, multi-turn simulations designed specifically to surface these behavioral gaps before agents reach production environments.
The goal is not simply to flag regressions, but to make structural weaknesses visible in a reproducible, CI-friendly way. When duplicate execution occurs under injected failure conditions, it is not noise. It is a signal about tool design and retry safety.
As we prepare to open-source a narrow, developer-first slice of this approach, the focus remains consistent: bring system-level behavioral testing into the development lifecycle early enough that engineers can act on it.
Because once agents operate in real workflows, duplicate execution is no longer theoretical.
It is a systems problem.
And systems problems demand discipline.
This is exactly the shift that needs to happen.
Evaluation measures reasoning quality.
Production safety lives at the execution layer.
Duplicate side effects aren’t hallucinations — they’re authority and state failures.
Agents don’t just generate language anymore. They mutate systems.
That changes the discipline required.